Git 常见用法(包含🌰)
Git 概念
Workspace:工作区
Index / Stage:暂存区
Repository:仓库区(或本地仓库)
Remote:远程仓库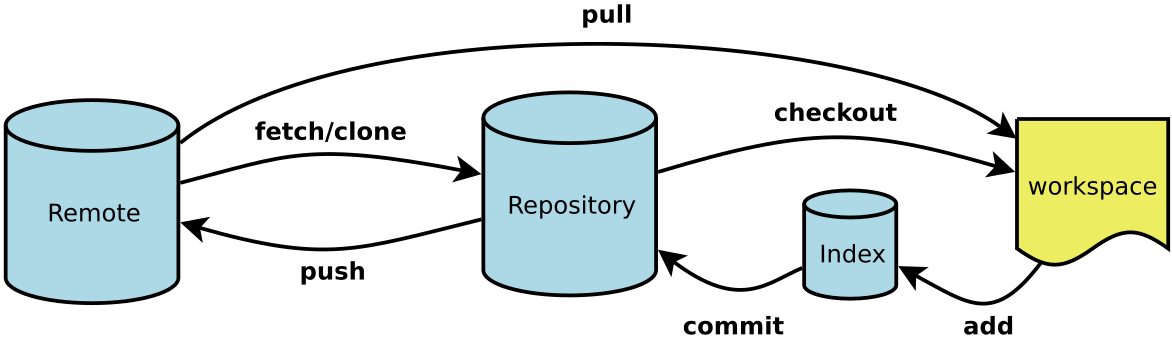
git HEAD
HEAD 是一个对当前检出记录的符号引用, 也就是指向你正在其基础上进行工作的提交记录。
HEAD 总是指向当前分支上最近一次提交记录。大多数修改提交树的 Git 命令都是从改变 HEAD 的指向开始的。
HEAD 通常情况下是指向分支名的(如 bugFix)。在你提交时,改变了 bugFix 的状态,这一变化通过 HEAD 变得可见。
1 | |
1 | |
git 相对引用
背景:通过指定提交记录哈希值的方式在 Git 中移动不太方便。在实际应用时,并没有像本程序中这么漂亮的可视化提交树供你参考,所以你就不得不用 git log 来查查看提交记录的哈希值,通过哈希值指定提交记录很不方便,所以 Git 引入了相对引用。这个就很厉害了!
使用相对引用的话,你就可以从一个易于记忆的地方(比如 bugFix 分支或 HEAD)开始计算。
相对引用非常给力,这里我介绍两个简单的用法:
1 | |
Git 常用语法
git config
配置 Git 的相关参数。
Git 一共有3个配置文件:
- 仓库级的配置文件:在仓库的 .git/.gitconfig,该配置文件只对所在的仓库有效。
- 全局配置文件:Mac 系统在 ~/.gitconfig,Windows 系统在 C:\Users<用户名>.gitconfig。
- 系统级的配置文件:在 Git 的安装目录下(Mac 系统下安装目录在 /usr/local/git)的 etc 文件夹中的 gitconfig。
1 | |
git clone
从远程仓库克隆一个版本库到本地。
1 | |
git init
初始化项目所在目录,初始化后会在当前目录下出现一个名为 .git 的目录。
1 | |
git status
查看本地仓库的状态。
1 | |
git remote
操作远程库。
1 | |
git branch
操作 Git 的分支命令。
1 | |
git checkout
检出命令,用于创建、切换分支等。
1 | |
git cherry-pick
把已经提交(多个/单个)的记录有序的合并到当前分支。关键词:多个/有序
1 | |
git add
把要提交的文件的信息添加到暂存区中。当使用 git commit 时,将依据暂存区中的内容来进行文件的提交
1 | |
git commit
将暂存区中的文件提交到本地仓库中。
1 | |
git fetch
git fetch 实际上将本地仓库中的远程分支更新成了远程仓库相应分支最新的状态。
git fetch 完成了仅有的但是很重要的两步:
- 从远程仓库下载本地仓库中缺失的提交记录
- 更新远程分支指针(如 origin/main)
git fetch 不会做的事:
- git fetch 并不会改变你本地仓库的状态。它不会更新你的 main 分支,也不会修改你磁盘上的文件。
理解这一点很重要,因为许多开发人员误以为执行了 git fetch 以后,他们本地仓库就与远程仓库同步了。它可能已经将进行这一操作所需的所有数据都下载了下来,但是并没有修改你本地的文件。
所以, 你可以将 git fetch 的理解为单纯的下载操作。
1 | |
git merge
合并分支
1 | |
git diff
比较版本之间的差异。
1 | |
git pull
从远程仓库获取最新版本并合并到本地。
首先会执行 git fetch,然后执行 git merge,把获取的分支的 HEAD 合并到当前分支。
1 | |
git push
把本地仓库的提交推送到远程仓库。远程仓库对应的分支会指向最新的提交,本地的远程分支也会指向最新的提交记录
1 | |
git log
显示提交的记录。
1 | |
git reset
还原提交记录。
1 | |
git revert
生成一个新的提交来撤销某次提交,此次提交之前的所有提交都会被保留。
1 | |
git tag
分支很容易被人为移动,并且当有新的提交时,它也会移动。分支很容易被改变,大部分分支还只是临时的,并且还一直在变。
你可能会问了:有没有什么可以永远指向某个提交记录的标识呢,比如软件发布新的大版本,或者是修正一些重要的 Bug 或是增加了某些新特性,有没有比分支更好的可以永远指向这些提交的方法呢?
当然有了!Git 的 tag 就是干这个用的啊,它们可以(在某种程度上 —— 因为标签可以被删除后重新在另外一个位置创建同名的标签)永久地将某个特定的提交命名为里程碑,然后就可以像分支一样引用了。
更难得的是,它们并不会随着新的提交而移动。你也不能切换到某个标签上面进行修改提交,它就像是提交树上的一个锚点,标识了某个特定的位置。
1 | |
git mv
重命名文件或者文件夹。
1 | |
git rm
删除文件或者文件夹。
1 | |
git rebase
Rebase 实际上就是取出一系列的提交记录,“复制”它们,然后在另外一个地方逐个的放下去。
Rebase 的优势就是可以创造更线性的提交历史,这听上去有些难以理解。如果只允许使用 Rebase 的话,代码库的提交历史将会变得异常清晰。
1 | |
git describe
由于标签在代码库中起着“锚点”的作用,Git 还为此专门设计了一个命令用来描述离你最近的锚点(也就是标签)
1 | |
git worktree
仅需维护一个 repo,又可以同时在多个 branch 上工作,互不影响
默认情况下, git init 或 git clone 初始化的 repo,只有一个 worktree,叫做 main worktree
在某一个目录下使用 Git 命令,当前目录下要么有 .git 文件夹;要么有 .git 文件,如果只有 .git 文件,里面的内容必须是指向 .git 文件夹的
1 | |
- 创建一个worktree目录结构
1
git worktree add ../feature/feature2cd ../feature/feature2/ 会发现,这个分支下并不存在 .git 文件夹,却存在一个 .git 文件,打开文件,内容如下:1
2
3├── amend-crash-demo
└── feature
└── feature21
gitdir: /Users/rgyb/Documents/projects/amend-crash-demo/.git/worktrees/feature2 - git worktree remove
1
2# 删除一个worktree 参数是文件路径 注意路径前不加 "/"
git worktree remove feature/feature21
2# 假设你创建一个 worktree,并在里面有改动,突然间这个worktree 又不需要了,此刻你按照上述命令是不能删掉了,此时就需要 -f 参数来帮忙了
git worktree remove -f feature/feature21
2
3# 删除了 worktree,其实在 Git 的文件中,还有很多 administrative 文件是没有用的,为了保持清洁,我们还需要进一步清理
# 这个命令就是清洁的兜底操作,可以让我们的工作始终保持整洁
git worktree prune
Git操作场景(🌰)
删除掉本地不存在的远程分支
多人合作开发时,如果远程的分支被其他开发删除掉,在本地执行 git branch –all 依然会显示该远程分支,可使用下列的命令进行删除
1 | |
只提交某次记录
发中经常会遇到的情况:我正在解决某个特别棘手的 Bug,为了便于调试而在代码中添加了一些调试命令并向控制台打印了一些信息。
这些调试和打印语句都在它们各自的提交记录里。最后我终于找到了造成这个 Bug 的根本原因,解决掉以后觉得沾沾自喜!
最后就差把 bugFix 分支里的工作合并回 main 分支了。你可以选择通过 fast-forward 快速合并到 main 分支上,但这样的话 main 分支就会包含我这些调试语句了。你肯定不想这样,应该还有更好的方式
1 | |
本地分支合并远端分支
1 | |
远程分支代码比本地分支代码新的情况进行提交
假设你周一克隆了一个仓库,然后开始研发某个新功能。到周五时,你新功能开发测试完毕,可以发布了。但是你的同事这周写了一堆代码,还改了许多你的功能中使用的 API,这些变动会导致你新开发的功能变得不可用。但是他们已经将那些提交推送到远程仓库了,因此你的工作就变成了基于项目旧版的代码,与远程仓库最新的代码不匹配了。
这种情况下, git push 就不知道该如何操作了。如果你执行 git push,Git 应该让远程仓库回到星期一那天的状态吗?还是直接在新代码的基础上添加你的代码,亦或由于你的提交已经过时而直接忽略你的提交?
因为这情况(历史偏离)有许多的不确定性,Git 是不会允许你 push 变更的。实际上它会强制你先合并远程最新的代码,然后才能分享你的工作。
1 | |
远程跟踪
自定义远程跟踪分支:你可以让任意分支跟踪 o/main, 然后该分支会像 main 分支一样得到隐含的 push 目的地以及 merge 的目标。 这意味着你可以在分支 totallyNotMain 上执行 git push,将工作推送到远程仓库的 main 分支上。
需要注意的是 main 并未被更新
有两种方法设置这个属性,第一种就是通过远程分支检出一个新的分支,执行:
1 | |
代码分支迁移到不同仓库
当我们需要将分支origin(A)/a 迁移到 origin(B)/a 并保留分支记录
1 | |
代码回滚(reset/revert)
- 结论
- git revert 后会多出一条commit,这里可进行回撤操作
- git reset 直接把之前 commit 删掉,非 git reset –hard 的操作是不会删掉修改代码,如果远程已经有之前代码,需要强推 git push -f
- 应用场景
- 如果回退分支的代码以后还需要的话用git revert就再好不过了;
- 如果分支我就是提错了没用了还不想让别人发现我错的代码,那就git reset吧
git reset
develop将a分支合并后,想要不留痕迹的撤回合并。这个时候用git reset就是很好的选择了1
2
3develop ----1 3-----
\ /
branch a a操作步骤
- 切换分支到develop
- git log 查看当前分支日志
- 我要将develop回退到合并之前的状态,那就是退到 commit 1这了,将commit号复制下来。退出编辑界面。
1
2
3
43.1 a分支的代码我不需要了,以后应该也不需要了
git reset 1(粘贴过来的commit号) --hard
3.2 a分支的代码我还需要
git reset 1(粘贴过来的commit号) - 将回退后的代码推送到远端 git push origin develop因为本地分支的代码落后于远端develop分支, 所以这一步需要强行推送 –force
1
2
3
4![rejected] develop -> develop (non-fast-forward)
error: 无法推送一些引用到 'git@github.cn:...'
提示:更新被拒绝,因为您当前分支的最新提交落后于其对应的远程分支。
。。。 - 强推
1
git push origin develop --force
git revert
还是之前的需求,不想要合并a,只想要没合并a时的样子。1
2
3develop ----1 3-----
\ /
branch a a操作步骤
- 切换分支到develop git checkout develop
- git log 查看当前分支日志
- 这次和git reset 不同的是我不能复制 commit 1这个commit号了,我需要复制的是commit 2的commit号。因为revert后面跟的是具体需要哪个已经合并了的分支,而并不是需要会退到哪的commit号。
1
git revert 2 - push到远端服务器
1
git push origin develop
解决合并代码 (Already up-to-date) 问题
- 有时我们合并代码会遇到冲突解决的问题, 这个时候如果想取消本次合并如果直接丢弃全部文件会照成远端代码还是保存了本次解决冲突的提交, 当我们重新再合并有冲突的代码就会显示Already up-to-date
- 接上个例子, 现在的需求是我之前已经把a分支revert了,但是我现在又需要a分支的代码了,我之前都写过一遍总不能再重新写一遍了。我首先想到的方法,把a分支再merge到develop不就好了。结果
1
git merge a因为我们之前提交合并的a分支的代码还在,因此我们并不能在重新合并a分支。1
Already up-to-date
解决方法: 使用revert之前revert的commit号。在上面的例子中就是git revert 4。于是又新增了一个commit,把之前revert的代码又重新revert回来了, 再继续执行合并操作代码冲突又会提示出来了